Řešení
Sjednoťte články, PDF dokumenty, ročenky i mediální obsah do jednoho chytrého vyhledávání, které uživatele navede rovnou k relevantnímu obsahu.
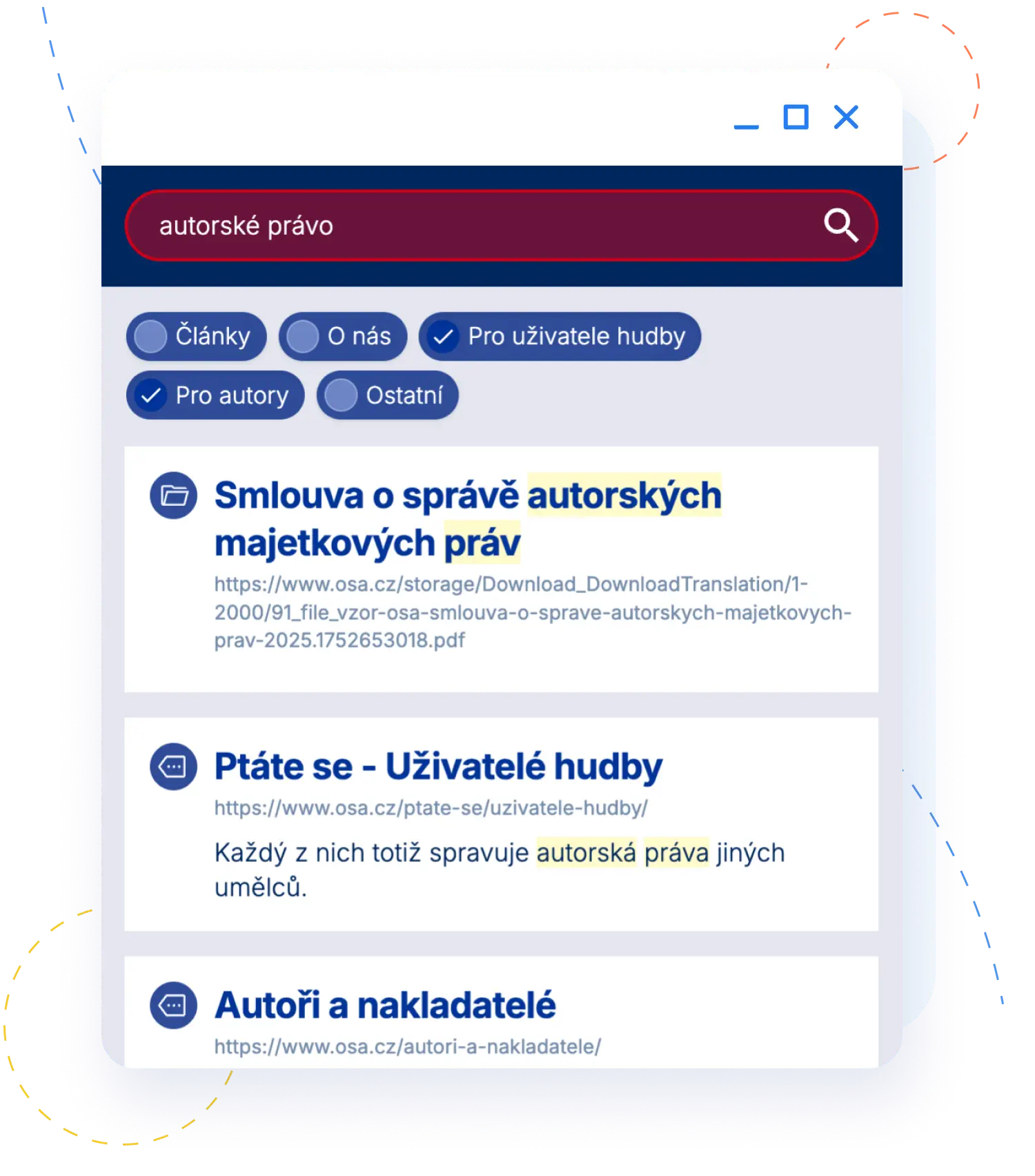
Organizace jako OSA spravují obrovské množství dat napříč doménami. Od aktuálních informací na hlavním webu, přes magazín Autor in, až po historický archiv nosičů a publikací. Každý den v textech a dokumentech hledá veřejnost i zaměstnanci, pro které je vyhledávání klíčovým pracovním nástrojem. Search Ready propojuje celý tento ekosystém do jednoho intuitivního okna.

Propojte vše – od dnešních bleskovek a reportáží po historické audiotéky a archivy. Čtenáři i redaktoři najdou odpověď na jeden klik a vy získáte ve svém obsahu absolutní pořádek.
Máte obsah roztříštěný na více doménách a v XML archivech? Pro Ochranný svaz autorský (OSA) jsme automaticky sjednotili 3 různé weby do 12 vyhledávacích indexů. Propojili jsme běžné webové stránky s rozsáhlými databázemi a historickými archivy.
Běžné stránky získáváme automatickým crawlerem, historické archivy (např. CD nebo VHS nosiče) napojíme z připravených XML dat.
Obsah je pro uživatele přehledně rozdělen – od Aktualit přes Články až po Archiv nosičů a Sazebníky.
Systém za běhu inteligentně ořezává příliš dlouhé a neformátované titulky článků na ideální délku, aby výsledky vždy vypadaly čistě.

Nejenže najdeme správný dokument, ale zobrazíme ho tam, kde ho uživatel čeká. Náš systém využívá AI k identifikaci obsahu a správnému pojmenování PDF souborů. Rozumí kontextu portálu – aktuální novinky a platné dokumenty tak mají automaticky přednost před historickým archivem.
AI analyzuje obsah PDF, pochopí jeho strukturu a automaticky mu doplní správný název. Díky OCR navíc plnohodnotně identifikujeme i rastrový obsah v PDF.
Systém rozumí kontextu vydavatele. Čerstvé novinky a platné dokumenty mají přednost před historickým archivem.
Automaticky detekujeme a označujeme PDF soubory jasnou ikonou i v případě, že jsou zdrojová data na webu neuspořádaná.
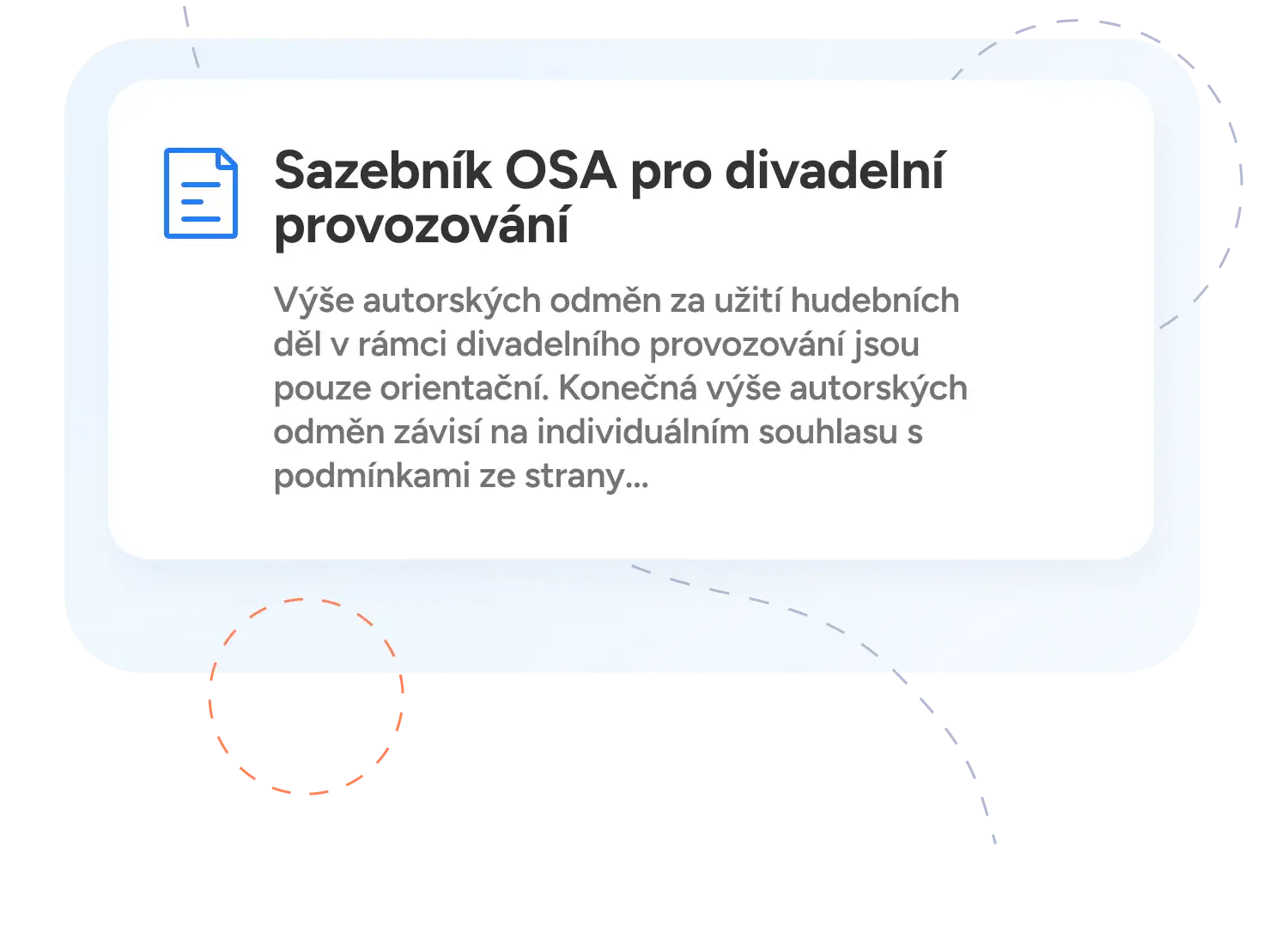
Proč nutit návštěvníky luštit, co se skrývá pod odkazem? Výsledky zobrazíme s kontextem a každý záznam automaticky opatříme vizuálním štítkem – třeba dokument, magazín nebo článek.
Vyhledávání stoprocentně respektuje značku. Uživatelé vidí odladěný vzhled s vašimi korporátními barvami a přehlednou strukturou.
Každý výsledek je automaticky na základě URL adresy (např. magazín, článek, ostatní) opatřen vizuálním štítkem. Čtenář se tak okamžitě orientuje.
Intuitivní prostředí ocení nejen veřejnost, ale i vaše interní týmy, které potřebují bleskově prohledávat vlastní gigantické archivy dat.
Kontaktujte nás a my se vám co nejdříve ozveme. Pobavíme se o vašich potřebách a zjistíme, zda je pro vás Search Ready vhodné řešení.
Jsme hrdým členem MEDIA FACTORY GROUP



